实现原理探究
实现原理探究
注意: 本版块难度很大,所有内容都作为选学内容。
如果学习Spring基本内容对你来说已经非常困难了,建议跳过此小节,直接进入MVC阶段的学习,此小节会从源码角度解释Spring的整个运行原理,对初学者来说等同于小学跨越到高中,它并不是必学内容,但是对于个人阅历提升极为重要(推荐完成整个SSM阶段的学习并且加以实战之后再来看此部分),如果你还是觉得自己能够跟上节奏继续深入钻研底层原理,那么现在就开始吧。
Bean工厂与Bean定义
实际上我们之前的所有操作都离不开一个东西,那就是IoC容器,那么它到底是如何实现呢?这一部分我们将详细介绍,首先我们大致了解一下ApplicationContext的加载流程:
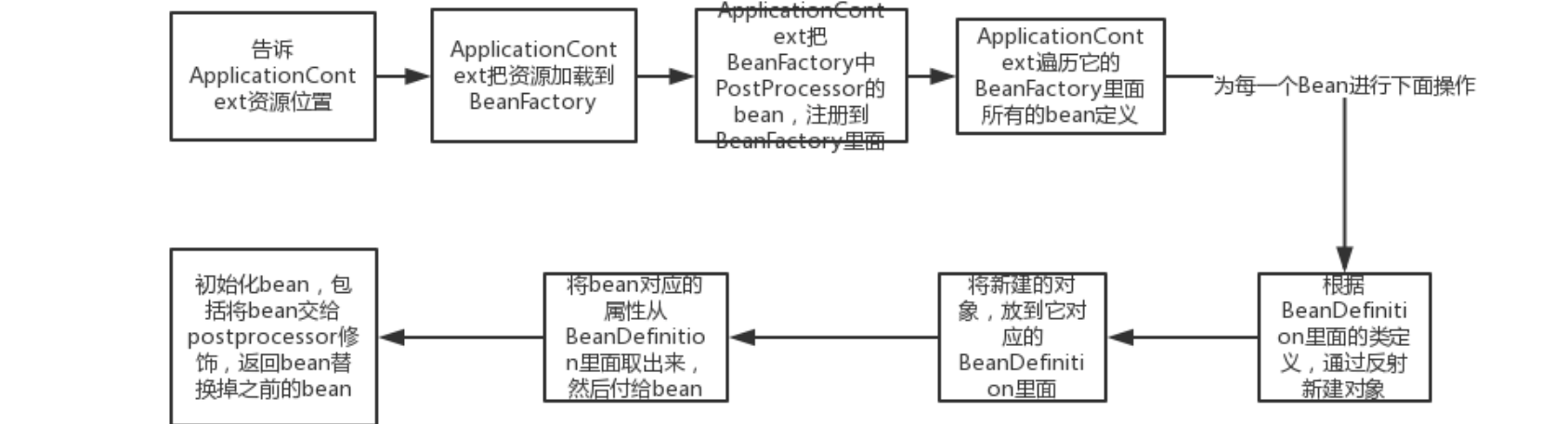
我们可以看到,整个过程极为复杂,一句话肯定是无法解释的。由于Spring的源码非常庞大,因此我们不可能再像了解其他框架那样直接自底向上逐行干源码了(各位可以自己点开看看,代码量非常多)

我们只能对几个关键部分进行介绍,在了解这些内容之后,实际上不需要完全阅读所有部分的源码都可以有一个大致的认识。
首先,容器既然要管理Bean,那么肯定需要一个完善的管理机制,实际上,对Bean的管理都是依靠BeanFactory在进行,顾名思义BeanFactory就是对Bean进行生产和管理的工厂,我们可以尝试自己创建和使用BeanFactory对象:
public static void main(String[] args) {
BeanFactory factory = new DefaultListableBeanFactory(); //这是BeanFactory的一个默认实现类
System.out.println("获取Bean对象:"+factory.getBean("lbwnb")); //我们可以直接找工厂获取Bean对象
}
我们可以直接找Bean工厂索要对象,只不过在一开始,工厂并不知道自己需要生产什么,可以生产什么,因此我们直接索要一个工厂不知道的Bean对象,会直接得到:


我们只有告诉工厂我们要生产什么,怎么生产,工厂才能开工:
public static void main(String[] args) {
DefaultListableBeanFactory factory = new DefaultListableBeanFactory(); //这是BeanFactory的一个默认实现类
BeanDefinition definition = BeanDefinitionBuilder //使用BeanDefinitionBuilder快速创建Bean定义
.rootBeanDefinition(Student.class) //Bean的类型
.setScope("prototype") //设置作用域为原型模式
.getBeanDefinition(); //生成此Bean定义
factory.registerBeanDefinition("lbwnb", definition); //向工厂注册Bean此定义,并设定Bean的名称
System.out.println(factory.getBean("lbwnb")); //现在就可以拿到了
}

实际上,我们的ApplicationContext中就维护了一个AutowireCapableBeanFactory对象:
public abstract class AbstractRefreshableApplicationContext extends AbstractApplicationContext {
@Nullable
private volatile DefaultListableBeanFactory beanFactory; //默认构造后存放在这里的是一个DefaultListableBeanFactory对象
...
@Override
public final ConfigurableListableBeanFactory getBeanFactory() { //getBeanFactory就可以直接得到上面的对象了
DefaultListableBeanFactory beanFactory = this.beanFactory;
if (beanFactory == null) {
throw new IllegalStateException("BeanFactory not initialized or already closed - " +
"call 'refresh' before accessing beans via the ApplicationContext");
}
return beanFactory;
}
我们可以尝试获取一下:
ApplicationContext context = new ClassPathXmlApplicationContext("application.xml");
//我们可以直接获取此对象
System.out.println(context.getAutowireCapableBeanFactory());
正是因为这样,ApplicationContext才具有了管理和生产Bean对象的能力。
不过,我们的配置可能是XML、可能是配置类,那么Spring要如何进行解析,将这些变成对应的BeanDefinition对象呢?使用BeanDefinitionReader就可以:
public static void main(String[] args) {
DefaultListableBeanFactory factory = new DefaultListableBeanFactory();
//比如我们要读取XML配置,我们直接使用XmlBeanDefinitionReader就可以快速进行扫描
XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(factory);
//加载此XML文件中所有的Bean定义到Bean工厂中
reader.loadBeanDefinitions(new ClassPathResource("application.xml"));
//可以看到能正常生产此Bean的实例对象
System.out.println(factory.getBean(Student.class));
}
因此,针对于不同类型的配置方式,ApplicationContext有着多种实现,其中常用的有:
- ClassPathXmlApplicationContext:适用于类路径下的XML配置文件。
- FileSystemXmlApplicationContext:适用于非类路径下的XML配置文件。
- AnnotationConfigApplicationContext:适用于注解配置形式。
比如ClassPathXmlApplicationContext在初始化的时候就会创建一个对应的XmlBeanDefinitionReader进行扫描:
@Override
protected void loadBeanDefinitions(DefaultListableBeanFactory beanFactory) throws BeansException, IOException {
// 为给定的BeanFactory创建XmlBeanDefinitionReader便于读取XML中的Bean配置
XmlBeanDefinitionReader beanDefinitionReader = new XmlBeanDefinitionReader(beanFactory);
// 各种配置,忽略掉
beanDefinitionReader.setEnvironment(this.getEnvironment());
...
// 配置完成后,直接开始加载XML文件中的Bean定义
loadBeanDefinitions(beanDefinitionReader);
}
protected void loadBeanDefinitions(XmlBeanDefinitionReader reader) throws BeansException, IOException {
Resource[] configResources = getConfigResources(); //具体加载过程我就不详细介绍了
if (configResources != null) {
reader.loadBeanDefinitions(configResources);
}
String[] configLocations = getConfigLocations();
if (configLocations != null) {
reader.loadBeanDefinitions(configLocations);
}
}
现在,我们就已经知道,Bean实际上是一开始通过BeanDefinitionReader进行扫描,然后将所有Bean以BeanDefinition对象的形式注册到对应的BeanFactory中进行集中管理,而我们使用的ApplicationContext实际上内部就有一个BeanFactory在进行Bean管理,这样容器才拥有了最基本的Bean管理功能。
当然,BeanFactory还可以具有父子关系,其中最关键的作用就是继承父容器中所有的Bean定义,这样的话,如果我们想要创建一个新的BeanFactory并且默认具有其他BeanFactory中所有的Bean定义外加一些其他的,那么就可以采用这种形式,这是很方便的。
我们可以来尝试一下,创建两个工厂:
public class Main {
public static void main(String[] args) {
DefaultListableBeanFactory factoryParent = new DefaultListableBeanFactory();
DefaultListableBeanFactory factoryChild = new DefaultListableBeanFactory();
//在父工厂中注册A
factoryParent.registerBeanDefinition("a", new RootBeanDefinition(A.class));
//在子工厂中注册B、C
factoryChild.registerBeanDefinition("b", new RootBeanDefinition(B.class));
factoryChild.registerBeanDefinition("c", new RootBeanDefinition(C.class));
//最后设定子工厂的父工厂
factoryChild.setParentBeanFactory(factoryParent);
}
static class A{ }
static class B{ }
static class C{ }
}
现在我们来看看是不是我们想的那样:
System.out.println(factoryChild.getBean(A.class)); //子工厂不仅能获取到自己的,也可以拿到父工厂的
System.out.println(factoryChild.getBean(B.class));
System.out.println(factoryChild.getBean(C.class));
System.out.println(factoryParent.getBean(B.class)); //注意父工厂不能拿到子工厂的,就像类的继承一样
同样的,我们在使用ApplicationContext时,也可以设定这样的父子关系,效果相同:
public static void main(String[] args) {
ApplicationContext contextParent = new ClassPathXmlApplicationContext("parent.xml");
ApplicationContext contextChild = new ClassPathXmlApplicationContext(new String[]{"child.xml"}, contextParent); //第一个参数只能用数组,奇怪
}
当然,除了这些功能之外,BeanFactory还提供了很多其他的管理Bean定义的方法,比如移除Bean定义、拷贝Bean定义、销毁单例Bean实例对象等功能,这里就不一一列出了,各位小伙伴自己调用一下测试就可以了,很简单。
单例Bean的创建与循环依赖
前面我们讲解了配置的Bean是如何被读取并加载到容器中的,接着我们来了解一下Bean实例对象是如何被创建并得到的,我们知道,如果要得到一个Bean的实例很简单,通过getBean方法就可以直接拿到了:
ApplicationContext context = new ClassPathXmlApplicationContext("application.xml");
System.out.println(context.getBean(Student.class)); //通过此方法就能快速得到
那么,一个Bean的实例对象到底是如何创建出来的呢?我们还要继续对我们之前讲解的BeanFactory进行深入介绍。
我们可以直接找到BeanFactory接口的一个抽象实现AbstractBeanFactory类,它实现了getBean()方法:
public Object getBean(String name) throws BeansException {
//套娃开始了,做好准备
return this.doGetBean(name, (Class)null, (Object[])null, false);
}
那么我们doGetBean()接着来看方法里面干了什么,这个方法比较长,我们分段进行讲解:
protected <T> T doGetBean(String name, @Nullable Class<T> requiredType, @Nullable Object[] args, boolean typeCheckOnly) throws BeansException {
String beanName = this.transformedBeanName(name); //虽然这里直接传的就是name,但是万一是别名呢,所以还得要解析一下变成原本的Bean名字
Object sharedInstance = this.getSingleton(beanName); //首先直接获取单例Bean对象
Object beanInstance;
if (sharedInstance != null && args == null) { //判断是否成功获取到共享的单例对象
...
因为所有的Bean默认都是单例模式,对象只会存在一个,因此它会先调用父类的getSingleton()方法来直接获取单例对象,如果有的话,就可以直接拿到Bean的实例。如果Bean不是单例模式,那么会进入else代码块。这一部分我们先来看单例模式下的处理,其实逻辑非常简单:
protected <T> T doGetBean(String name, @Nullable Class<T> requiredType, @Nullable Object[] args, boolean typeCheckOnly) throws BeansException {
...
if (sharedInstance != null && args == null) {
if (this.logger.isTraceEnabled()) {
//这里会判断Bean是否为正在创建状态,为什么会有这种状态呢?我们会在后面进行介绍
if (this.isSingletonCurrentlyInCreation(beanName)) {
this.logger.trace("Returning eagerly cached instance of singleton bean '" + beanName + "' that is not fully initialized yet - a consequence of a circular reference");
} else {
this.logger.trace("Returning cached instance of singleton bean '" + beanName + "'");
}
}
//这里getObjectForBeanInstance会进行最终处理
//因为Bean有两个特殊的类型,工厂Bena和空Bean,所以说需要单独处理
//如果是普通Bean直接原样返回beanInstance接收到最终结果
beanInstance = this.getObjectForBeanInstance(sharedInstance, name, beanName, (RootBeanDefinition)null);
} else {
...
}
//最后还会进行一次类型判断,如果都没问题,直接返回beanInstance作为结果,我们就得到Bean的实例对象了
return this.adaptBeanInstance(name, beanInstance, requiredType);
}
实际上整个单例Bean的创建路线还是很清晰的,并没有什么很难理解的地方,在正常情况下,其实就是简单的创建对象实例并返回即可。
其中最关键的是它对于循环依赖的处理。我们发现,在上面的代码中,得到单例对象后,会有一个很特殊的判断isSingletonCurrentlyInCreation,这个是干嘛的?对象不应该直接创建出来吗?为什么会有这种正在创建的状态呢?我们来探究一下。
开始之前先给大家提个问题:
现在有两个Bean,A和B都是以原型模式进行创建,而A中需要注入B,B中需要注入A,这时就会出现A还未创建完成,就需要B,而B这时也没创建完成,因为B需要A,而A等着B,B又等着A,这样就只能无限循环下去了(就像死锁那种感觉)所以就出现了循环依赖的问题(同理,一个对象注入自己,还有三个对象之间,甚至多个对象之间也会出现这种情况)
但是,在单例模式下,由于每个Bean只会创建一个实例,只要能够处理好对象之间的引用关系,Spring完全有机会解决单例对象循环依赖的问题。那么单例模式下是如何解决循环依赖问题的呢?
我们回到一开始的getSingleton()方法中,研究一下它到底是如何处理循环依赖的,它是可以自动解决循环依赖问题的:
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName);
//先从第一层列表中拿Bean实例,拿到直接返回
if (singletonObject == null && this.isSingletonCurrentlyInCreation(beanName)) {
//如果第一层拿不到,并且已经认定为处于循环状态,看看第二层有没有
singletonObject = this.earlySingletonObjects.get(beanName);
//要是还是没有,继续往下
if (singletonObject == null && allowEarlyReference) {
synchronized(this.singletonObjects) {
//加锁再执行一次上述流程
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
//仍然没有获取到实例,只能从singletonFactory中获取了
ObjectFactory<?> singletonFactory = (ObjectFactory)this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
//丢进earlySingletonObjects中,下次就可以直接在第二层拿到了
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}
看起来很复杂,实际上它使用了三级缓存的方式来处理循环依赖的问题,包括:
- singletonObjects,用于保存实例化、注入、初始化完成的 bean 实例
- earlySingletonObjects,用于保存实例化完成的 bean 实例
- singletonFactories,在初始创建Bean对象时都会生成一个对应的单例工厂用于获取早期对象
我们先来画一个流程图理清整个过程:
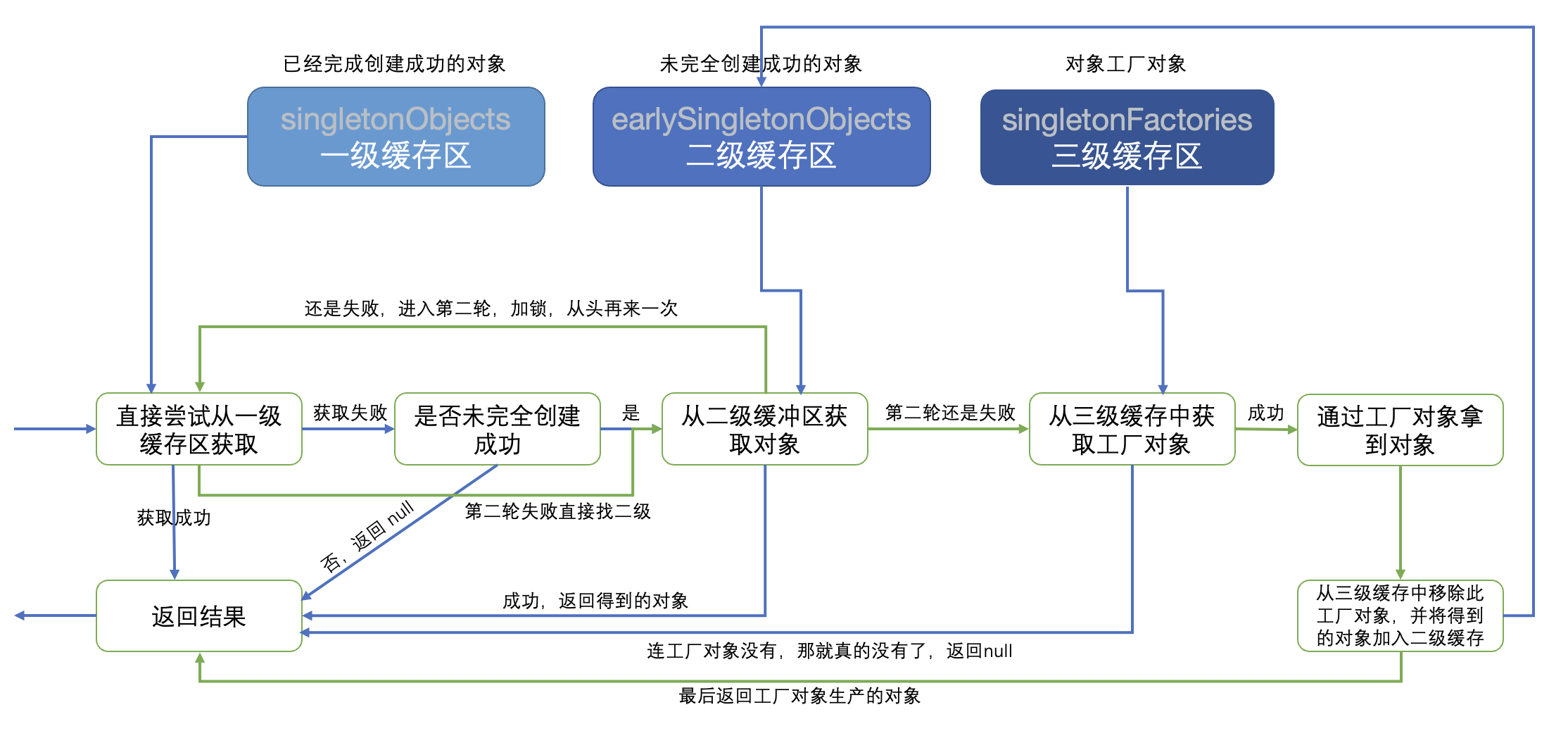
我们在了解这个流程之前,一定要先明确,单例Bean对象的获取,会有哪些结果,首先就是如果我们获取的Bean压根就没在工厂中注册,那得到的结果肯定是null;其次,如果我们获取的Bean已经注册了,那么肯定就可以得到这个单例对象,只是不清楚创建到哪一个阶段了。
现在我们根据上面的流程图,来模拟一下A和B循环依赖的情况:
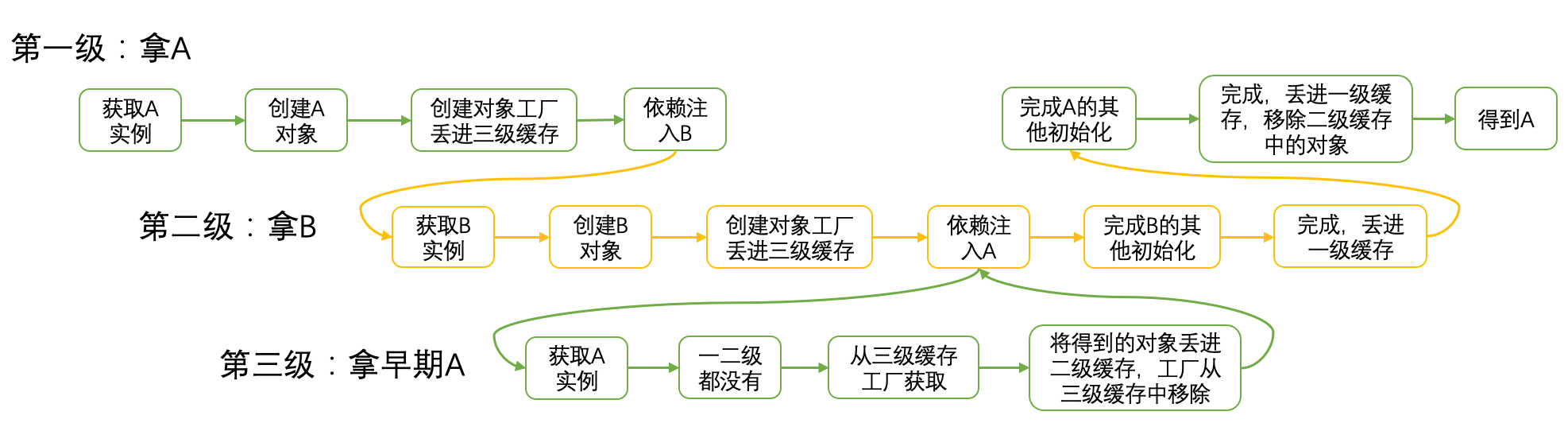
有的小伙伴就会有疑问了,看起来似乎两级缓存也可以解决问题啊,干嘛搞三层而且还搞个对象工厂?这不是多此一举吗?实际上这是为了满足Bean的生命周期而做的,通过工厂获取早期对象代码如下:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
//这里很关键,会对一些特别的BeanPostProcessor进行处理,比如AOP代理相关的,如果这个Bean是被AOP代理的,我们需要得到的是一个经过AOP代理的对象,而不是直接创建出来的对象,这个过程需要BeanPostProcessor来完成(AOP产生代理对象的逻辑是在属性填充之后,因此只能再加一级进行缓冲)
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (SmartInstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().smartInstantiationAware) {
exposedObject = bp.getEarlyBeanReference(exposedObject, beanName);
}
}
return exposedObject;
}
我们会在后面的部分中详细介绍BeanPostProcessor以及AOP的实现原理,届时各位再回来看就会明白了。
后置处理器与AOP
接着我们来介绍一下PostProcessor,它其实是Spring提供的一种后置处理机制,它可以让我们能够插手Bean、BeanFactory、BeanDefinition的创建过程,相当于进行一个最终的处理,而最后得到的结果(比如Bean实例、Bean定义等)就是经过后置处理器返回的结果,它是整个加载过程的最后一步。
而AOP机制正是通过它来实现的,我们首先来认识一下第一个接口BeanPostProcessor,它相当于Bean初始化的一个后置动作,我们可以直接实现此接口:
//注意它后置处理器也要进行注册
@Component
public class TestBeanProcessor implements BeanPostProcessor {
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
System.out.println(beanName); //打印bean的名称
return bean;
}
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
return BeanPostProcessor.super.postProcessBeforeInitialization(bean, beanName);
}
}
我们发现,此接口中包括两个方法,一个是postProcessAfterInitialization用于在Bean初始化之后进行处理,还有一个postProcessBeforeInitialization用于在Bean初始化之前进行处理,注意这里的初始化不是创建对象,而是调用类的初始化方法,比如:
@Component
public class TestBeanProcessor implements BeanPostProcessor {
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
System.out.println("我是之后:"+beanName);
return bean; //这里返回的Bean相当于最终的结果了,我们依然能够插手修改,这里返回之后是什么就是什么了
}
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
System.out.println("我是之前:"+beanName);
return bean; //这里返回的Bean会交给下一个阶段,也就是初始化方法
}
}
@Component
public class TestServiceImpl implements TestService{
public TestServiceImpl(){
System.out.println("我是构造方法");
}
@PostConstruct
public void init(){
System.out.println("我是初始化方法");
}
TestMapper mapper;
@Autowired
public void setMapper(TestMapper mapper) {
System.out.println("我是依赖注入");
this.mapper = mapper;
}
...
而TestServiceImpl的加载顺序为:
现在我们再来总结一下一个Bean的加载流程:
[Bean定义]首先扫描Bean,加载Bean定义 -> [依赖注入]根据Bean定义通过反射创建Bean实例 -> [依赖注入]进行依赖注入(顺便解决循环依赖问题)-> [初始化Bean]BeanPostProcessor的初始化之前方法 -> [初始化Bean]Bean初始化方法 -> [初始化Bean]BeanPostProcessor的初始化之后方法 -> [完成]最终得到的Bean加载完成的实例
利用这种机制,理解Aop的实现过程就非常简单了,AOP实际上也是通过这种机制实现的,它的实现类是AnnotationAwareAspectJAutoProxyCreator,而它就是在最后对Bean进行了代理,因此最后我们得到的结果实际上就是一个动态代理的对象(有关详细实现过程,这里就不进行列举了,感兴趣的可以继续深入)因此,实际上之前设计的三层缓存,都是由于需要处理AOP设计的,因为在Bean创建得到最终对象之前,很有可能会被PostProcessor给偷梁换柱!
那么肯定有人有疑问了,这个类没有被注册啊,那按理说它不应该参与到Bean的初始化流程中的,为什么它直接就被加载了呢?
还记得@EnableAspectJAutoProxy吗?我们来看看它是如何定义就知道了:
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Import({AspectJAutoProxyRegistrar.class})
public @interface EnableAspectJAutoProxy {
boolean proxyTargetClass() default false;
boolean exposeProxy() default false;
}
我们发现它使用了@Import来注册AspectJAutoProxyRegistrar,那么这个类又是什么呢,我们接着来看:
class AspectJAutoProxyRegistrar implements ImportBeanDefinitionRegistrar {
AspectJAutoProxyRegistrar() {
}
public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry) {
//注册AnnotationAwareAspectJAutoProxyCreator到容器中
AopConfigUtils.registerAspectJAnnotationAutoProxyCreatorIfNecessary(registry);
AnnotationAttributes enableAspectJAutoProxy = AnnotationConfigUtils.attributesFor(importingClassMetadata, EnableAspectJAutoProxy.class);
if (enableAspectJAutoProxy != null) {
if (enableAspectJAutoProxy.getBoolean("proxyTargetClass")) {
AopConfigUtils.forceAutoProxyCreatorToUseClassProxying(registry);
}
if (enableAspectJAutoProxy.getBoolean("exposeProxy")) {
AopConfigUtils.forceAutoProxyCreatorToExposeProxy(registry);
}
}
}
}
它实现了接口,这个接口也是Spring提供的一种Bean加载机制,它支持直接向容器中添加Bean定义,容器也会加载这个Bean:
- ImportBeanDefinitionRegistrar类只能通过其他类@Import的方式来加载,通常是启动类或配置类。
- 使用@Import,如果括号中的类是ImportBeanDefinitionRegistrar的实现类,则会调用接口中方法(一般用于注册Bean)
- 实现该接口的类拥有注册bean的能力。
我们可以看到此接口提供了一个BeanDefinitionRegistry正是用于注册Bean的定义的。
因此,当我们打上了@EnableAspectJAutoProxy注解之后,首先会通过@Import加载AspectJAutoProxyRegistrar,然后调用其registerBeanDefinitions方法,然后使用工具类注册AnnotationAwareAspectJAutoProxyCreator到容器中,这样在每个Bean创建之后,如果需要使用AOP,那么就会通过AOP的后置处理器进行处理,最后返回一个代理对象。
我们也可以尝试编写一个自己的ImportBeanDefinitionRegistrar实现,首先编写一个测试Bean:
public class TestBeanDefinitionRegistrar implements ImportBeanDefinitionRegistrar {
@Override
public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry) {
BeanDefinition definition = BeanDefinitionBuilder.rootBeanDefinition(Student.class).getBeanDefinition();
registry.registerBeanDefinition("lbwnb", definition);
}
}
观察控制台输出,成功加载Bean实例。
与BeanPostProcessor差不多的还有BeanFactoryPostProcessor,它和前者一样,也是用于我们自己处理后置动作的,不过这里是用于处理BeanFactory加载的后置动作,BeanDefinitionRegistryPostProcessor直接继承自BeanFactoryPostProcessor,并且还添加了新的动作postProcessBeanDefinitionRegistry,你可以在这里动态添加Bean定义或是修改已经存在的Bean定义,这里我们就直接演示BeanDefinitionRegistryPostProcessor的实现:
@Component
public class TestDefinitionProcessor implements BeanDefinitionRegistryPostProcessor {
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) throws BeansException {
System.out.println("我是Bean定义后置处理!");
BeanDefinition definition = BeanDefinitionBuilder.rootBeanDefinition(TestBean.class).getBeanDefinition();
registry.registerBeanDefinition("lbwnb", definition);
}
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory configurableListableBeanFactory) throws BeansException {
System.out.println("我是Bean工厂后置处理!");
}
}
在这里注册Bean定义其实和之前那种方法效果一样。
最后,我们再完善一下Bean加载流程(加粗部分是新增的):
[Bean定义]首先扫描Bean,加载Bean定义 -> [Bean定义]Bean定义和Bean工厂后置处理 -> [依赖注入]根据Bean定义通过反射创建Bean实例 -> [依赖注入]进行依赖注入(顺便解决循环依赖问题)-> [初始化Bean]BeanPostProcessor的初始化之前方法 -> [初始化Bean]Bean初始化方法 -> [初始化Bean]BeanPostProcessor的初始化之前后方法 -> [完成]最终得到的Bean加载完成的实例
应用程序上下文详解
前面我们详细介绍了BeanFactory是如何工作的,接着我们来研究一下ApplicationContext的内部,实际上我们真正在项目中使用的就是ApplicationContext的实现,那么它又是如何工作的呢。
public interface ApplicationContext extends EnvironmentCapable, ListableBeanFactory, HierarchicalBeanFactory, MessageSource, ApplicationEventPublisher, ResourcePatternResolver {
@Nullable
String getId();
String getApplicationName();
String getDisplayName();
long getStartupDate();
@Nullable
ApplicationContext getParent();
AutowireCapableBeanFactory getAutowireCapableBeanFactory() throws IllegalStateException;
}
它本身是一个接口,同时集成了多种类型的BeanFactory接口,说明它应该具有这些BeanFactory的能力,实际上我们在前面已经提到过,ApplicationContext是依靠内部维护的BeanFactory对象来完成这些功能的,并不是它本身就实现了这些功能。
这里我们就先从构造方法开始走起,以我们常用的AnnotationConfigApplicationContext为例:
public AnnotationConfigApplicationContext(Class<?>... componentClasses) {
this(); //1. 首先会调用自己的无参构造
register(componentClasses); //2. 然后注册我们传入的配置类
refresh(); //3. 最后进行刷新操作(关键)
}
先来看第一步:
public GenericApplicationContext() {
//父类首先初始化内部维护的BeanFactory对象
this.beanFactory = new DefaultListableBeanFactory();
}
public AnnotationConfigApplicationContext() {
StartupStep createAnnotatedBeanDefReader = this.getApplicationStartup().start("spring.context.annotated-bean-reader.create");
//创建AnnotatedBeanDefinitionReader对象,用于后续处理 @Bean 注解
this.reader = new AnnotatedBeanDefinitionReader(this);
createAnnotatedBeanDefReader.end();
//创建ClassPathBeanDefinitionScanner对象,用于扫描类路径上的Bean
this.scanner = new ClassPathBeanDefinitionScanner(this);
}
这样,AnnotationConfigApplicationContext的基本内容就初始化好了,不过这里结束之后会将ConfigurationClassPostProcessor后置处理器加入到BeanFactory中,它继承自BeanFactoryPostProcessor,也就是说一会会在BeanFactory初始化完成之后进行后置处理:
public AnnotatedBeanDefinitionReader(BeanDefinitionRegistry registry, Environment environment) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
Assert.notNull(environment, "Environment must not be null");
this.registry = registry;
this.conditionEvaluator = new ConditionEvaluator(registry, environment, null);
//这里注册了注解处理配置相关的后置处理器
AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry);
}
实际上这个后置处理器的主要目的就是为了读取配置类中的各种Bean定义以及其他注解,比如@Import、@ComponentScan等。
同时这里也会注册一个AutowiredAnnotationBeanPostProcessor后置处理器到BeanFactory,它继承自BeanPostProcessor,用于处理后续生成的Bean对象,其实看名字就知道,这玩意就是为了处理@Autowire、@Value这种注解,用于自动注入,这里就不深入讲解具体实现了。
所以,第一步结束之后,就会有这两个关键的后置处理器放在容器中:

接着是第二步,注册配置类:
@Override
public void register(Class<?>... componentClasses) {
Assert.notEmpty(componentClasses, "At least one component class must be specified");
StartupStep registerComponentClass = this.getApplicationStartup().start("spring.context.component-classes.register")
.tag("classes", () -> Arrays.toString(componentClasses));
//使用我们上面创建的Reader注册配置类
this.reader.register(componentClasses);
registerComponentClass.end();
}
现在配置类已经成功注册到IoC容器中了,我们接着来看第三步,到目前为止,我们已知的仅仅是注册了配置类的Bean,而刷新操作就是配置所有Bean的关键部分了,刷新操作是在 AbstractApplicationContext 中实现的:
@Override
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
StartupStep contextRefresh = this.applicationStartup.start("spring.context.refresh");
// 准备当前应用程序上下文,进行刷新、设置启动事件和活动标志以及执行其他初始化
prepareRefresh();
// 这个方法由子类实现,对内部维护的BeanFactory进行刷新操作,然后返回这个BeanFactory
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// 初始化配置Bean工厂,比如一些会用到的类加载器和后置处理器。
prepareBeanFactory(beanFactory);
try {
// 由子类实现对BeanFactory的其他后置处理,目前没有看到有实现
postProcessBeanFactory(beanFactory);
StartupStep beanPostProcess = this.applicationStartup.start("spring.context.beans.post-process");
// 实例化并调用所有注册的 BeanFactoryPostProcessor 类型的Bean
// 这一步中,上面提到的BeanFactoryPostProcessor就开始工作了,比如包扫描、解析Bean配置等
// 这一步结束之后,包扫描到的其他Bean就注册到BeanFactory中了
invokeBeanFactoryPostProcessors(beanFactory);
// 实例化并注册所有 BeanPostProcessor 类型的 Bean,不急着执行
registerBeanPostProcessors(beanFactory);
beanPostProcess.end();
initMessageSource();
initApplicationEventMulticaster();
// 依然是提供给子类实现的,目的是用于处理一些其他比较特殊的Bean,目前似乎也没看到有实现
onRefresh();
// 注册所有的监听器
registerListeners();
// 将剩余所有非懒加载单例Bean全部实例化
finishBeanFactoryInitialization(beanFactory);
finishRefresh();
} catch (BeansException ex) {
...
// 发现异常直接销毁所有Bean
destroyBeans();
// 取消本次刷新操作,重置标记
cancelRefresh(ex);
// 继续往上抛异常
throw ex;
} finally {
resetCommonCaches();
contextRefresh.end();
}
}
}
所以,现在流程就很清晰了,实际上最主要的就是refresh方法,它从初始化到实例化所有的Bean整个流程都已经完成,在这个方法结束之后,整个IoC容器基本就可以正常使用了。
我们继续来研究一下finishBeanFactoryInitialization方法,看看它是怎么加载所有Bean的:
protected void finishBeanFactoryInitialization(ConfigurableListableBeanFactory beanFactory) {
...
beanFactory.preInstantiateSingletons(); //套娃
}
@Override
public void preInstantiateSingletons() throws BeansException {
...
// 列出全部bean名称
List<String> beanNames = new ArrayList<>(this.beanDefinitionNames);
// 开始初始化所有Bean
for (String beanName : beanNames) {
//得到Bean定义
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
//Bean不能是抽象类、不能是非单例模式、不能是懒加载的
if (!bd.isAbstract() && bd.isSingleton() && !bd.isLazyInit()) {
//针对于Bean和FactoryBean分开进行处理
if (isFactoryBean(beanName)) {
Object bean = getBean(FACTORY_BEAN_PREFIX + beanName);
if (bean instanceof SmartFactoryBean<?> smartFactoryBean && smartFactoryBean.isEagerInit()) {
getBean(beanName);
}
} else {
getBean(beanName); //最后都是通过调用getBean方法来初始化实例,这里就跟我们之前讲的连起来了
}
}
}
...
}
至此,关于Spring容器核心加载流程,我们就探究完毕了,实际 单易懂,就是代码量太大了。在后续的SpringBoot阶段,我们还会继续深挖Spring的某些机制的具体实现细节。
Mybatis整合原理
通过之前的了解,我们再来看Mybatis的@MapperScan是如何实现的,现在理解起来就非常简单了。
我们可以直接打开查看:
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE})
@Documented
@Import({MapperScannerRegistrar.class})
@Repeatable(MapperScans.class)
public @interface MapperScan {
String[] value() default {};
String[] basePackages() default {};
...
我们发现,和Aop一样,它也是通过Registrar机制,通过@Import来进行Bean的注册,我们来看看MapperScannerRegistrar是个什么东西,关键代码如下:
void registerBeanDefinitions(AnnotationMetadata annoMeta, AnnotationAttributes annoAttrs, BeanDefinitionRegistry registry, String beanName) {
BeanDefinitionBuilder builder = BeanDefinitionBuilder.genericBeanDefinition(MapperScannerConfigurer.class);
builder.addPropertyValue("processPropertyPlaceHolders", true);
...
}
虽然很长很多,但是这些代码都是在添加一些Bean定义的属性,而最关键的则是最上方的MapperScannerConfigurer,Mybatis将其Bean信息注册到了容器中,那么这个类又是干嘛的呢?
public class MapperScannerConfigurer implements BeanDefinitionRegistryPostProcessor, InitializingBean, ApplicationContextAware, BeanNameAware {
private String basePackage;
它实现了BeanDefinitionRegistryPostProcessor,也就是说它为Bean信息加载提供了后置处理,我们接着来看看它在Bean信息后置处理中做了什么:
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) {
if (this.processPropertyPlaceHolders) {
this.processPropertyPlaceHolders();
}
//初始化类路径Mapper扫描器,它相当于是一个工具类,可以快速扫描出整个包下的类定义信息
//ClassPathMapperScanner是Mybatis自己实现的一个扫描器,修改了一些扫描规则
ClassPathMapperScanner scanner = new ClassPathMapperScanner(registry);
scanner.setAddToConfig(this.addToConfig);
scanner.setAnnotationClass(this.annotationClass);
scanner.setMarkerInterface(this.markerInterface);
scanner.setSqlSessionFactory(this.sqlSessionFactory);
scanner.setSqlSessionTemplate(this.sqlSessionTemplate);
scanner.setSqlSessionFactoryBeanName(this.sqlSessionFactoryBeanName);
scanner.setSqlSessionTemplateBeanName(this.sqlSessionTemplateBeanName);
scanner.setResourceLoader(this.applicationContext);
scanner.setBeanNameGenerator(this.nameGenerator);
scanner.setMapperFactoryBeanClass(this.mapperFactoryBeanClass);
if (StringUtils.hasText(this.lazyInitialization)) {
scanner.setLazyInitialization(Boolean.valueOf(this.lazyInitialization));
}
if (StringUtils.hasText(this.defaultScope)) {
scanner.setDefaultScope(this.defaultScope);
}
//添加过滤器,这里会配置为所有的接口都能被扫描(因此即使你不添加@Mapper注解都能够被扫描并加载)
scanner.registerFilters();
//开始扫描
scanner.scan(StringUtils.tokenizeToStringArray(this.basePackage, ",; \t\n"));
}
开始扫描后,会调用doScan()方法,我们接着来看(这是ClassPathMapperScanner中的扫描方法):
public Set<BeanDefinitionHolder> doScan(String... basePackages) {
Set<BeanDefinitionHolder> beanDefinitions = super.doScan(basePackages);
//首先从包中扫描所有的Bean定义
if (beanDefinitions.isEmpty()) {
LOGGER.warn(() -> {
return "No MyBatis mapper was found in '" + Arrays.toString(basePackages) + "' package. Please check your configuration.";
});
} else {
//处理所有的Bean定义,实际上就是生成对应Mapper的代理对象,并注册到容器中
this.processBeanDefinitions(beanDefinitions);
}
//最后返回所有的Bean定义集合
return beanDefinitions;
}
通过断点我们发现,最后处理得到的Bean定义发现此Bean是一个MapperFactoryBean,它不同于普通的Bean,FactoryBean相当于为普通的Bean添加了一层外壳,它并不是依靠Spring直接通过反射创建,而是使用接口中的方法:
public interface FactoryBean<T> {
String OBJECT_TYPE_ATTRIBUTE = "factoryBeanObjectType";
@Nullable
T getObject() throws Exception;
@Nullable
Class<?> getObjectType();
default boolean isSingleton() {
return true;
}
}
通过getObject()方法,就可以获取到Bean的实例了。
注意这里一定要区分FactoryBean和BeanFactory的概念:
- BeanFactory是个Factory,也就是 IOC 容器或对象工厂,所有的 Bean 都是由 BeanFactory( 也就是 IOC 容器 ) 来进行管理。
- FactoryBean是一个能生产或者修饰生成对象的工厂Bean(本质上也是一个Bean),可以在BeanFactory(IOC容器)中被管理,所以它并不是一个简单的Bean。当使用容器中factory bean的时候,该容器不会返回factory bean本身,而是返回其生成的对象。要想获取FactoryBean的实现类本身,得在getBean(String BeanName)中的BeanName之前加上&,写成getBean(String &BeanName)。
我们也可以自己编写一个实现:
@Component("test")
public class TestFb implements FactoryBean<Student> {
@Override
public Student getObject() throws Exception {
System.out.println("获取了学生");
return new Student();
}
@Override
public Class<?> getObjectType() {
return Student.class;
}
}
public static void main(String[] args) {
log.info("项目正在启动...");
ApplicationContext context = new AnnotationConfigApplicationContext(TestConfiguration.class);
System.out.println(context.getBean("&test")); //得到FactoryBean本身(得加个&搞得像C语言指针一样)
System.out.println(context.getBean("test")); //得到FactoryBean调用getObject()之后的结果
}
因此,实际上我们的Mapper最终就以FactoryBean的形式,被注册到容器中进行加载了:
public T getObject() throws Exception {
return this.getSqlSession().getMapper(this.mapperInterface);
}
这样,整个Mybatis的@MapperScan的原理就全部解释完毕了。
在了解完了Spring的底层原理之后,我们其实已经完全可以根据这些实现原理来手写一个Spring框架了。