消息队列
那么,什么是消息队列呢?
我们之前如果需要进行远程调用,那么一般可以通过发送HTTP请求来完成,而现在,我们可以使用第二种方式,就是消息队列,它能够将发送方发送的信息放入队列中,当新的消息入队时,会通知接收方进行处理,一般消息发送方称为生产者,接收方称为消费者。

这样我们所有的请求,都可以直接丢到消息队列中,再由消费者取出,不再是直接连接消费者的形式了,而是加了一个中间商,这也是一种很好的解耦方案,并且在高并发的情况下,由于消费者能力有限,消息队列也能起到一个削峰填谷的作用,堆积一部分的请求,再由消费者来慢慢处理,而不会像直接调用那样请求蜂拥而至。
那么,消息队列具体实现有哪些呢:
- RabbitMQ - 性能很强,吞吐量很高,支持多种协议,集群化,消息的可靠执行特性等优势,很适合企业的开发。
- Kafka - 提供了超高的吞吐量,ms级别的延迟,极高的可用性以及可靠性,而且分布式可以任意扩展。
- RocketMQ - 阿里巴巴推出的消息队列,经历过双十一的考验,单机吞吐量高,消息的高可靠性,扩展性强,支持事务等,但是功能不够完整,语言支持性较差。
我们这里,主要讲解的是RabbitMQ消息队列。
See RabbitMQ
SpringCloud 消息组件
前面我们已经学习了如何使用RabbitMQ消息队列,接着我们来简单介绍一下SpringCloud为我们提供的一些消息组件。
SpringCloud Stream
官方文档: https://docs.spring.io/spring-cloud-stream/docs/3.2.2/reference/html/
前面我们介绍了RabbitMQ,了解了消息队列相关的一些操作,但是可能我们会遇到不同的系统在用不同的消息队列,比如系统A用的Kafka、系统B用的RabbitMQ,但是我们现在又没有学习过Kafka,那么怎么办呢?有没有一种方式像JDBC一样,我们只需要关心SQL和业务本身,而不用关心数据库的具体实现呢?
SpringCloud Stream能够做到,它能够屏蔽底层实现,我们使用统一的消息队列操作方式就能操作多种不同类型的消息队列。
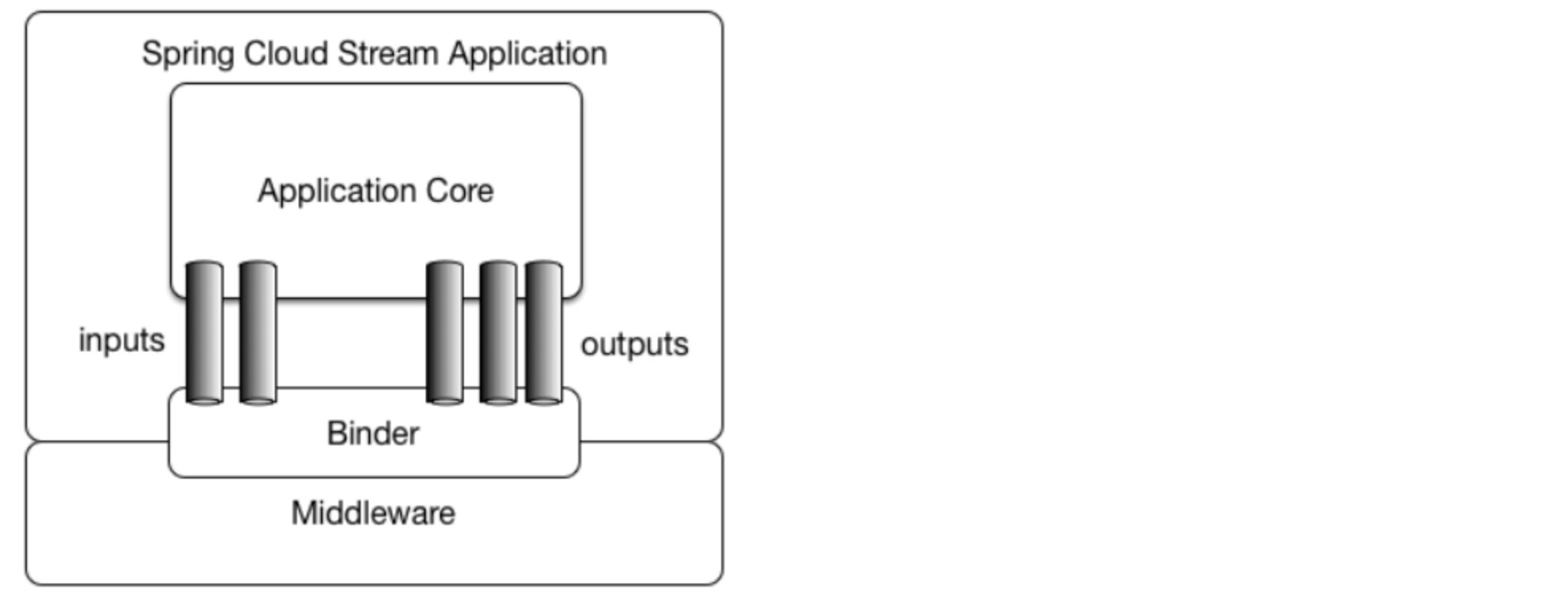
它屏蔽了RabbitMQ底层操作,让我们使用统一的Input和Output形式,以Binder为中间件,这样就算我们切换了不同的消息队列,也无需修改代码,而具体某种消息队列的底层实现是交给Stream在做的。
这里我们创建一个新的项目来测试一下:

依赖如下:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>2021.0.1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependencies>
<!-- RabbitMQ的Stream实现 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
首先我们来编写一下生产者,首先是配置文件:
server:
port: 8001
spring:
cloud:
stream:
binders: #此处配置要绑定的rabbitmq的服务信息
local-server: #绑定名称,随便起一个就行
type: rabbit #消息组件类型,这里使用的是RabbitMQ,就填写rabbit
environment: #服务器相关信息,按照下面的方式填写就行,爆红别管
spring:
rabbitmq:
host: 192.168.0.6
port: 5672
username: admin
password: admin
virtual-host: /test
bindings:
test-out-0:
destination: test.exchange
接着我们来编写一个Controller,一会访问一次这个接口,就向消息队列发送一个数据:
@RestController
public class PublishController {
@Resource
StreamBridge bridge; //通过bridge来发送消息
@RequestMapping("/publish")
public String publish(){
//第一个参数其实就是RabbitMQ的交换机名称(数据会发送给这个交换机,到达哪个消息队列,不由我们决定)
//这个交换机的命名稍微有一些规则:
//输入: <名称> + -in- + <index>
//输出: <名称> + -out- + <index>
//这里我们使用输出的方式,来将数据发送到消息队列,注意这里的名称会和之后的消费者Bean名称进行对应
bridge.send("test-out-0", "HelloWorld!");
return "消息发送成功!"+new Date();
}
}
现在我们来将生产者启动一下,访问一下接口:

可以看到消息成功发送,我们来看看RabbitMQ这边的情况:

新增了一个test-in-0交换机,并且此交换机是topic类型的:

但是目前没有任何队列绑定到此交换机上,因此我们刚刚发送的消息实际上是没有给到任何队列的。
接着我们来编写一下消费者,消费者的编写方式比较特别,只需要定义一个Consumer就可以了,其他配置保持一致:
@Component
public class ConsumerComponent {
@Bean("test") //注意这里需要填写我们前面交换机名称中"名称",这样生产者发送的数据才会正确到达
public Consumer<String> consumer(){
return System.out::println;
}
}
配置中需要修改一下目标交换机:
server:
port: 8002
spring:
cloud:
stream:
...
bindings:
#因为消费者是输入,默认名称为 方法名-in-index,这里我们将其指定为我们刚刚定义的交换机
test-in-0:
destination: test.exchange
接着我们直接启动就可以了,可以看到启动之后,自动为我们创建了一个新的队列:

而这个队列实际上就是我们消费者等待数据到达的队列:
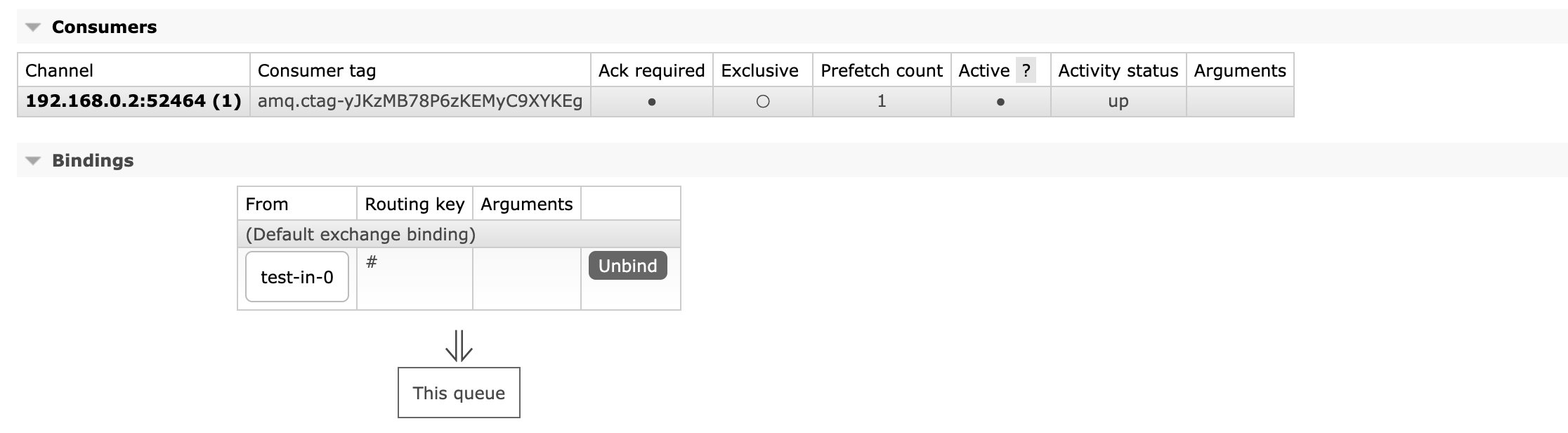
可以看到当前队列直接绑定到了我们刚刚创建的交换机上,并且routingKey是直接写的#,也就是说一会消息会直接过来。
现在我们再来访问一些消息发送接口:


可以看到消费者成功地进行消费了:

这样,我们就通过使用SpringCloud Stream来屏蔽掉底层RabbitMQ来直接进行消息的操作了。
SpringCloud Bus
官方文档: https://cloud.spring.io/spring-cloud-bus/reference/html/
实际上它就相当于是一个消息总线,可用于向各个服务广播某些状态的更改(比如云端配置更改,可以结合Config组件实现动态更新配置,当然我们前面学习的Nacos其实已经包含这个功能了)或其他管理指令。
这里我们也是简单使用一下吧,Bus需要基于一个具体的消息队列实现,比如RabbitMQ或是Kafka,这里我们依然使用RabbitMQ。
我们将最开始的微服务拆分项目继续使用,比如现在我们希望借阅服务的某个接口调用时,能够给用户服务和图书服务发送一个通知,首先是依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bus-amqp</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
接着我们只需要在配置文件中将RabbitMQ的相关信息配置:
spring:
rabbitmq:
addresses: 192.168.0.6
username: admin
password: admin
virtual-host: /test
management:
endpoints:
web:
exposure:
include: "*" #暴露端点,一会用于提醒刷新
然后启动我们的三个服务器,可以看到在管理面板中:

新增了springCloudBug这样一个交换机,并且:

自动生成了各自的消息队列,这样就可以监听并接收到消息了。
现在我们访问一个端口:
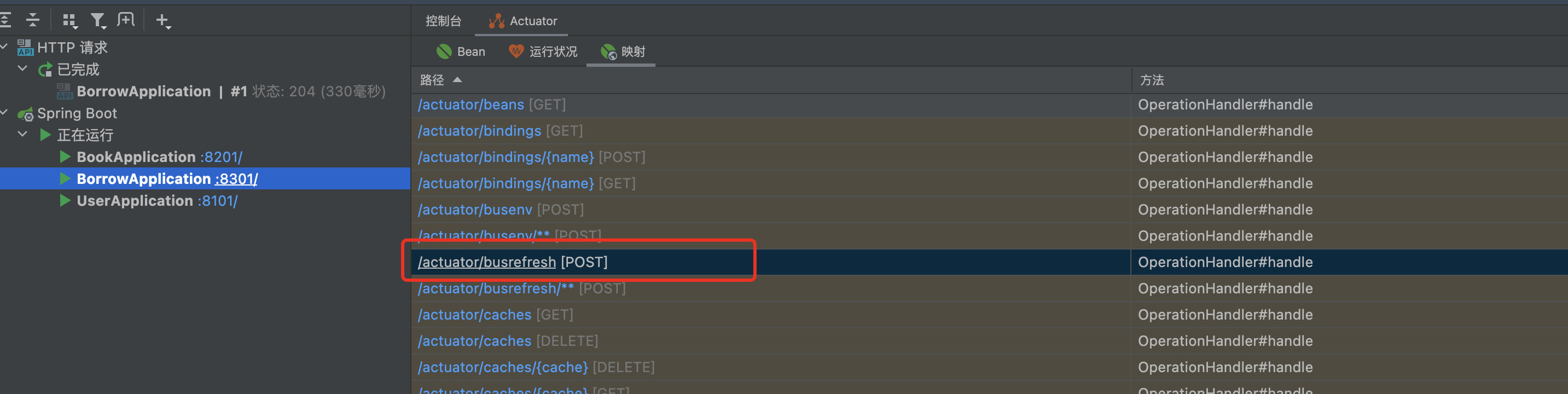
此端口是用于通知别人进行刷新,可以看到调用之后,消息队列中成功出现了一次消费:

现在我们结合之前使用的Config配置中心,来看看是不是可以做到通知之后所有的配置动态刷新了。